Orchestrating data flows throughout their whole life cycle
Orchestrer les flux de données tout au long de leur cycle de vie
Résumé
Most life science domains rely on the massive production of data via different technologies (sequencing, imaging, proteomics, metabolomics, phenomics, …). In this context, data management becomes critical to enhance the value of the data to its full extent. This situation translates into regulatory obligations for research projects, with incentives for researchers to adopt best practice in data management. The FAIR principles, which aim at making the data Findable, Accessible, Interoperable, and Reusable, are a cornerstone of best practice. They are widely promoted at the political level, but they require appropriate software tools to be put into practice.
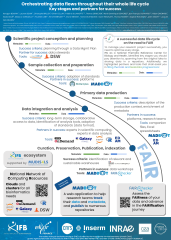
We present here a general schema describing the successive steps for seamless data management from the conception of a research project until result publication and data deposition in relevant repositories. Data management plans (DMPs), often perceived as a tedious administrative requirement, could turn into much-appreciated support for researchers if they were adapted to fit their concrete needs (e.g. identifying datasets for reuse, reprocessing, etc.). This would require user-friendly tools to handle DMPs, which should not only serve as landmarks at the onset, mid-term, and termination of a project but offer interactive interfaces enabling their continuous follow-up throughout the project, and designed modularly to cope with the diversity of data combined in a project.
DMPs should also promote the adoption of international standards and specifications established by communities of experts for each data type, which become an absolute requirement to deposit data in international repositories. Validating the compliance and quality of the metadata along the project’s life will save the painful efforts necessary to recollect mandatory information at the moment of data submission, months or years after their generation. Metadata standardization should rely on domain-specific ontologies such as EDAM, to describe the data types, formats, and operations, as well as general purpose lightweight ontologies (e.g. Schema.org/Bioschemas, DC-Terms, DCAT) to increase findability and reuse. Data management software environments should also handle provenance metadata such as the location of primary and secondary data generated at each step of a project, to optimize storage usage, avoid data loss, and ensure data securing without excessive duplication. It should also include user-friendly interfaces to simplify data and metadata submission to international repositories, and to automate their indexing in national and international catalogs.
Beyond the description of these conceptual requirements, we will present the software tools and standards required to accompany each event associated with the data and metadata (production, curation, storage, archiving, …). Some of these tools have been developed by the Institut Français de Bioinformatique or by the European bioinformatics infrastructure ELIXIR. Other tools are under development or have to be developed to achieve a comprehensive software environment supporting the orchestration of data flows throughout their life cycle.
Domaines
Sciences du Vivant [q-bio]
Fichier principal
 poster_IFB_orchestration flux de données_JOBIM_2024.pdf (1.59 Mo)
Télécharger le fichier
poster_IFB_orchestration flux de données_JOBIM_2024.pdf (1.59 Mo)
Télécharger le fichier
| Origine | Fichiers produits par l'(les) auteur(s) |
|---|---|
| licence |



